GSOC 2025 - Converting Demucs v4 (Hybrid Transformer) AI model to ONNX format
Imagine loading any track in Mixxx and instantly isolating the vocals, drums, bass, or instruments live, in real time. This is the vision behind our Google Summer of Code 2025 project: "Converting Demucs v4 (Hybrid Transformer) AI model to ONNX format".
Mixxx 2.6 will support playback of stem files containing separate channels for different instruments. These stems can come from the original studio recordings (or DAW exports), or be generated using modern AI-based stem separation tools when the original stems aren’t available.
Demucs v4 is a state-of-the-art open-source music stem separation model developed by Alexandre Défossez [1]. It uses deep neural networks to "unmix" songs into separate instrument tracks - such as vocals, drums, bass, and others - by learning patterns from thousands of examples of how these instruments sound in isolation. While it provides exceptional quality in separating songs into stems, it is currently implemented in Python and therefore cannot be used directly in C++ applications or run efficiently on hardware accelerators.
This project is a step towards supporting real-time stem separation within Mixxx, by exporting the Python-based Demucs model to ONNX - the Open Neural Network Exchange format. ONNX is an open standard for representing machine learning models, allowing them to run on many platforms and hardware accelerators through compatible runtimes such as ONNX Runtime (ORT).
The key contributions of this project are:
- Preparing the Demucs code for ONNX export by rewriting non-exportable operations
- Validating all the modified parts with numerical tests to ensure export of existing model weights without the need for retraining.
- Scripts for exporting ONNX and ORT compatible formats of the model.
- Example scripts for deployment of ONNX model with C++ using ONNX Runtime.
- Benchmarking the exported model for performance and separation quality.
- Upstream PR with our modifications to the Demucs repository
- Conference talk to be delivered at the ADC 2025
Introduction
Source separation models are typically developed using Python-based libraries such as PyTorch or TensorFlow, which require a Python runtime to execute machine learning models. This dependency can make it challenging to use these models in environments where Python is not available or practical, such as audio plugins, which are often written in C++. To address this, ONNX (Open Neural Network Exchange) has become a widely adopted representation format, enabling language-independent deployment of machine learning models.
While both PyTorch and TensorFlow provide straightforward ONNX export for simple models, complex audio models like Demucs often present significant hurdles. This is primarily due to their use of complex tensors and custom implementations of operations like Short-time Fourier Transform (STFT) and Inverse Short-time Fourier Transform (ISTFT), which are not natively supported by ONNX. As a result, previous attempts to export Demucs to ONNX have typically bypassed these operations, requiring developers to reimplement STFT/ISTFT in every target language, a process that is both error prone and time consuming.
In this project, we successfully exported Demucs v4 as a fully self-contained ONNX model, by rewriting the STFT and ISTFT operations to be ONNX compatible. This means the model can be used directly in any language that supports ONNX, greatly simplifying integration for audio developers and enabling broader adoption of source separation technology.
A key part of our approach was to diagnose and address each export issue step by step, developing custom numerical tests to ensure that our ONNX-compatible replacements matched the original PyTorch calculations as closely as possible. This was crucial, as retraining the model was not a viable option: Demucs was originally trained on a large private dataset over weeks using multiple GPUs, and reproducing those results without the dataset and computational resources would be extremely difficult. We verified the rewritten layers against the original PyTorch implementation to ensure equivalence (mean squared error(MSE) < 1e-4). By focusing on numerical fidelity, we ensured that the exported model retained the high performance of the original, without the need for retraining.
Understanding the Math Behind Audio
Before diving into transforms and neural networks, it helps to review how audio is represented mathematically and why complex numbers and Fourier transforms are so central to signal processing.
Real Numbers (Time-Domain Audio)
Digital audio is simply a sequence of real numbers — samples taken at regular time intervals.
Example: a 44.1 kHz stereo track stores 44,100 real values per second per channel.
Each value (e.g. 0.25, -0.67) represents instantaneous amplitude (air pressure or voltage).
Complex Numbers (Frequency Representation)
To analyze frequencies, we extend real numbers to complex numbers.
A complex number represents both amplitude and phase of a frequency - like a small arrow (vector) that encodes how strong a frequency is and how it’s shifted in time.
In audio processing, complex numbers appear when converting sound waves into their frequency components using the Fourier Transform.
Where:
- \(a\): real part, \(b\): imaginary part, \(i^2 = -1\)
Complex numbers are often represented in polar form:
Where:
- \(r = \sqrt{a^2 + b^2}\) (magnitude)
- \(\theta = {atan2}(b, a)\) (phase angle)
Conversions:
- \(r = \sqrt{a^2 + b^2}\), \(\theta = \operatorname{atan2}(b, a)\), \(a = r \cos\theta\), \(b = r \sin\theta\)
In signal processing:
- Magnitude → strength of each frequency component.
- Phase → timing/offset of that frequency’s oscillation.
Complex numbers allow us to represent both amplitude and phase, making them perfect for describing sound in the frequency domain.
From Time to Frequency: FFT, STFT, and ISTFT
Fourier Transform (FT)
The Fourier Transform expresses a signal as a sum of sine and cosine waves of different frequencies.
For digital (sampled) signals, we use the Discrete Fourier Transform (DFT):
Its inverse reconstructs the signal:
Where:
- \(x[n]\) is the time-domain signal (length \(N\))
- \(X[k]\) is the frequency-domain representation (DFT coefficients)
- \(n\) is the time index, \(k\) is the frequency bin
For example, with a 4-sample input:
- Input: \([1, 2, 3, 4]\)
- DFT: \([10, -2+2i, -2, -2-2i]\) (frequency components)
- IDFT: Reconstructs the original signal from its DFT.
Short-Time Fourier Transform (STFT)
A single DFT gives the overall frequency content but ignores when things happen. To capture time-varying frequency information, we use the Short-Time Fourier Transform.
Steps:
- Split the signal into short, overlapping frames (e.g. 2048 samples).
- Apply a window (Hann/Hamming) to each frame.
- Compute the FFT of each windowed frame.
Mathematically:
\(X(m,\omega) = \sum_n x[n] \, w[n - m] \, e^{-j \omega n}\)
- \(m\): frame index (time)
- \(\omega\): frequency bin
- Output: complex spectrogram showing how frequency content evolves over time.
A spectrogram is a 2-D matrix (time × frequency) of complex values - often visualized by plotting magnitude in dB.
Inverse STFT (ISTFT)
To go back to the time domain:
- Compute inverse FFT for each frame.
- Multiply by a synthesis window if required.
- Overlap-add frames to reconstruct the waveform.
Errors here cause audible artifacts (clicks, smearing, or phase shifts).
Understanding HTDemucs and the Challenges with ONNX Export
To understand the export process, it’s important to look closely at how HTDemucs (Hybrid Transformer Demucs) is structured, and why its architecture introduces challenges when converting to the ONNX format.
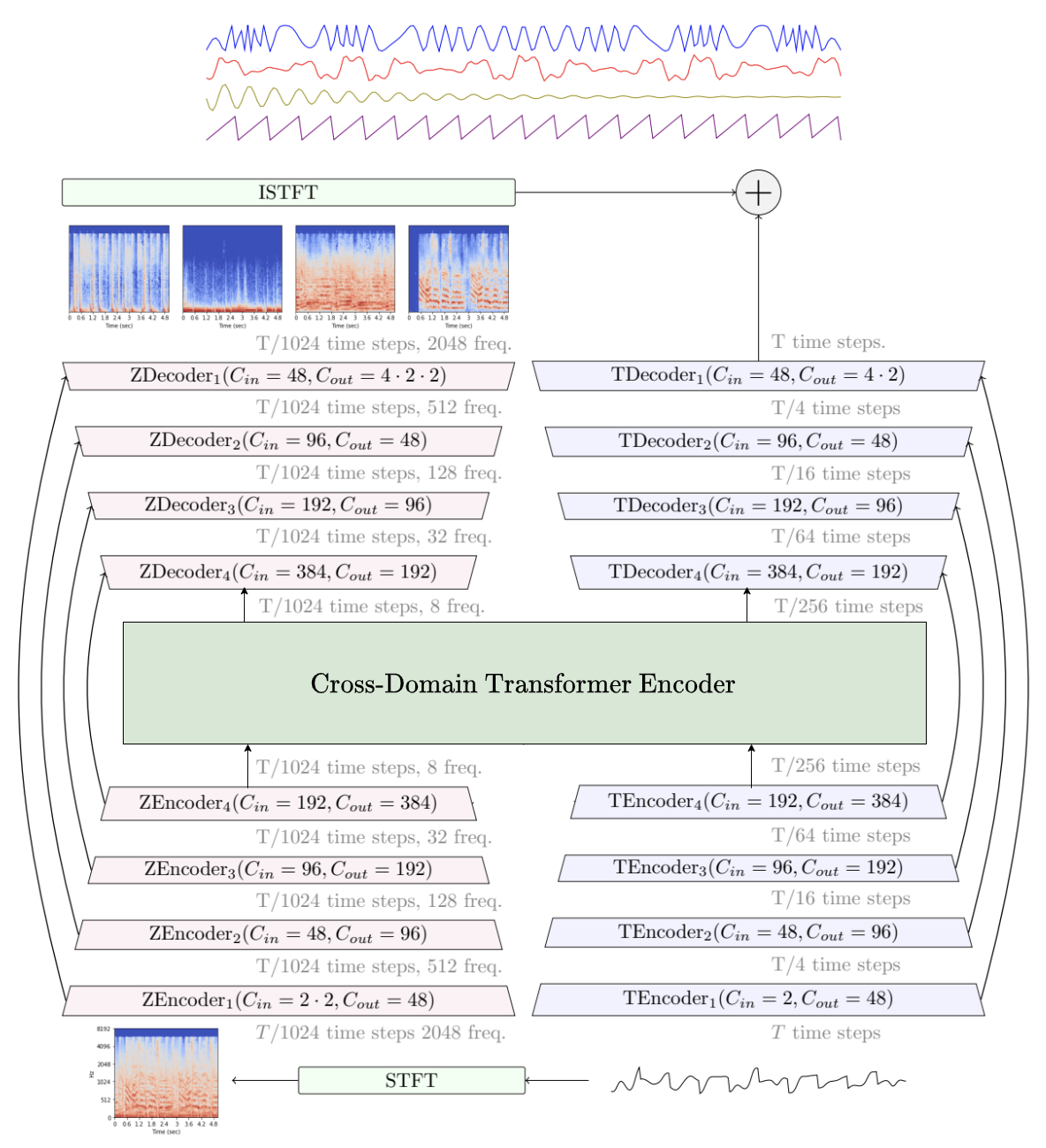
Figure 1. Architecture of the HTDemucs model (source: facebookresearch/demucs, licensed under MIT License).
HTDemucs Explained
Unlike text-based AI models like Open AI's GPT that learn language patterns, Demucs is an audio model trained to recognize patterns in sound waves. It doesn’t understand lyrics or meaning - instead, it detects subtle spectral and temporal cues that distinguish instruments, like how the human ear can separate a singer from the drums.
Hybrid Transformer(HT) Demucs or Demucs v4 is a hybrid model - it combines two parallel processing branches:
Time-Domain Branch
- Operates directly on the raw waveform (real-valued input).
- Uses temporal convolutions and Transformer blocks to learn how each instrument evolves over time.
Time-Frequency Domain Branch
- Operates on the signal’s spectrogram, obtained by applying a Short-Time Fourier Transform (STFT).
- The STFT produces a complex-valued tensor, representing both magnitude and phase across time and frequency.
- The model immediately converts this to a magnitude spectrogram, a purely real-valued representation, which is then processed by convolutional and Transformer layers.
- At the end of this branch, an Inverse STFT (ISTFT) is applied to reconstruct the real-valued waveform.
These two branches are then fused to produce the final stem-separated outputs (vocals, drums, bass, and others).
The ONNX Export Problem
The key difficulty in exporting HTDemucs lies in ONNX’s lack of support for complex tensors.
- In the time-domain branch, all operations are real-valued and export cleanly to ONNX.
- In the time-frequency branch, two specific operations, STFT and ISTFT, involve complex numbers.
The rest of the model (all convolutional, transformer, and linear layers) operates purely on real numbers, and therefore poses no export issue.
ONNX, as of current opset versions, does not fully support:
- Complex-valued tensors as native types - PyTorch Issue
- Complex FFT operations (
torch.stft,torch.istft) from PyTorch - PyTorch Issue
As a result, a direct torch.onnx.export() call on HTDemucs fails, since the exporter encounters unsupported complex operations.
Our Solution
Real-Valued STFT and ISTFT Rewrites
Because complex tensors appear only in the STFT and ISTFT stages, we reimplemented these operations using pairs of real-valued tensors that store the sine and cosine components separately.
Mathematically, this represents the same information as complex numbers (real + imaginary parts), but it avoids using complex datatypes that ONNX does not support.
1. STFT Rewrite
Instead of using torch.stft(), we expressed the Fourier transform as a set of 1-D convolutions with precomputed sine and cosine kernels.
This allows us to compute: \(\text{Re}(X) = x * \cos(\omega)\), \(\text{Im}(X) = -x * \sin(\omega)\)
Thus, we can store the real and imaginary parts as separate real-valued tensors, fully ONNX-compatible.
2. ISTFT Rewrite
Similarly, for inverse reconstruction:
- The original ISTFT combines complex values through real + imaginary synthesis.
- We reconstructed the time-domain signal by performing the same series of overlap-add and cosine/sine inverse convolutions, again using only real-valued tensors.
By carefully ensuring numerical equivalence to PyTorch’s implementation, we achieved perfect parity (MSE < 1e-4) between the original and rewritten layers.
Final Export
The only problematic parts were the STFT and ISTFT layers, and once these were rewritten with real-valued math, the model exported fully and cleanly to ONNX — no retraining required.
This approach made it possible to:
- Preserve the original model weights.
- Ensure perfect numerical equivalence.
- Achieve seamless ONNX export compatible with ONNX Runtime (ORT) and C++ deployment.
Unified Benchmarking: Timing and SI-SDR
To evaluate the exported ONNX model, we developed benchmarking scripts for both PyTorch and ONNX/ORT backends. Key features:
- Separation Backend:
- PyTorch: Runs separation using the original Demucs model.
- ONNX: Runs separation by invoking the ONNX CLI tool via subprocess, matching the workflow of the provided example scripts.
- Timing:
- The script records detailed timing for each track, printing and saving the results.
- SI-SDR Evaluation:
- Computes the SI-SDR (Scale-Invariant Signal-to-Distortion Ratio) for each separated track using the
torchmetricslibrary. - Output:
- Results are saved in timestamped folders, with timing and SI-SDR metrics output to JSON files named according to the backend (e.g.,
benchmark_results_cpp.json).
How to Run the Benchmark
- Download MusDB dataset following the instructions in documentation
- For C++ benchmarking, ensure the CLI tool is built and ONNX model has been exported.
- Run the benchmark script:
python benchmark-pytorch.py/benchmark-cpp-onnx.py --musdb-root /path/to/musdb-hq/
- Review the JSON results for timing and SI-SDR metrics.
Benchmark Results
The quality of the model is expected to be equal or slightly worse when exported to ONNX. While there are plenty of ways of measuring the benchmarks models (another blog post incoming), we've chosen to measure our models with SI-SDR metric, Scale Invariant Signal To Distortion Ratio, on the MusDB dataset. This is the standard metric on which researchers report their source separation model's performance.
We conducted comprehensive benchmarking on both CPU and GPU platforms, evaluating 50 tracks from the MusDB test dataset (approximately 3.46 hours of audio).
CPU Performance Comparison
| Metric | PyTorch Model | C++ ONNX Model | Improvement |
|---|---|---|---|
| Total Processing Time | 5,380.35 sec | 4,415.30 sec | 17.94% faster |
| Processing Time for 1 min input | 25.89 sec | 21.24 sec | 17.94% faster |
GPU Performance Comparison
| Metric | PyTorch Model (GPU) | Python ONNXRuntime (GPU) | Difference |
|---|---|---|---|
| Total Processing Time | 354.13 sec | 386.40 sec | 8.35% slower |
| Processing Time for 1 min input | 1.70 sec | 1.86 sec | 8.35% slower |
Audio Quality Results
| Stem | PyTorch Model (dB) | ONNX Model (C++) (dB) |
|---|---|---|
| drums.wav | 9.46 | 9.47 |
| bass.wav | 7.76 | 7.77 |
| other.wav | 4.69 | 4.65 |
| vocals.wav | 7.84 | 7.83 |
| Overall | 7.44 | 7.43 |
Table: SI-SDR (dB) comparison for each stem and overall, using torchmetrics. Results are shown for the native PyTorch model and the exported ONNX model running in C++. Higher SI-SDR values indicate better separation quality (less distortion).
Typical high-performing models achieve around 7–9 dB on vocals in the MusDB benchmark - with 0 dB meaning no separation improvement over the original mixture.
Key Findings:
- CPU Performance: The C++ ONNX model delivers significant performance improvements (17.94% faster) while maintaining equivalent audio quality
- GPU Performance: PyTorch maintains a performance advantage on GPU (8.35% faster), likely due to optimized CUDA implementations
- Audio Quality: Both implementations produce nearly identical separation quality across all stems (< 0.1 dB difference)
Now that we have a running platform independent high quality ONNX Demucs model that can utilize hardware acceleration and be deployed with C++, we plan to integrate this into Mixxx DJ for future. We've prepared example scripts for running the exported Demucs model, which can be used following the instructions documented in our READMEs.
Plans for future integration into Mixxx
Here's a list of all the PRs that document our incremental changes towards exporting Demucs:
| Task | PR Status | PR Link |
|---|---|---|
| ONNX Computation Path | Merged | PR #1 |
| STFT Rewrite | Merged | PR #2 |
| Inverse STFT Rewrite | Merged | PR #4 |
| ONNX Export Scripts | Merged | PR #5 |
| CI for model export | Merged | PR #6 |
| Example C++ Scripts | In Review | PR #7 |
| Benchmarking Scripts | In Review | PR #9 |
We've raised a PR with all our Demucs modifications to the upstream here - Demucs PR Link.
A talk will be presented on this project at the Audio Developers Conference 2025 in Bristol.
Finally, we've created this EPIC to track all issues related to merging Demucs to Mixxx. Feel free to join the discussion and get involved with supporting real time stems separation inside Mixxx.
🙏 Acknowledgements
This project would not have been possible without the extraordinary support and mentorship of Jörg, whose guidance, thoughtful reviews, and timely feedback shaped the project from start to finish. His expertise and encouragement were invaluable throughout every stage.
A huge thank you also to Antoine, who not only mentored me during the project but also integrated the exported ONNX model into his open-source tool Stemgen, deploying it using Rust and ONNX Runtime. Seeing the model already being used in a real-world application is deeply rewarding.
Finally, I would like to thank the entire Mixxx community and Google Summer of Code program for providing me the opportunity to undertake this challenging endeavour and the right environment to support its successful completion.
References
[1] A. Défossez, “Hybrid Transformers for Music Source Separation,” arXiv preprint arXiv:2211.08553, 2022.
Available: https://arxiv.org/abs/2211.08553

Comments